Data science tools to study local policy-making
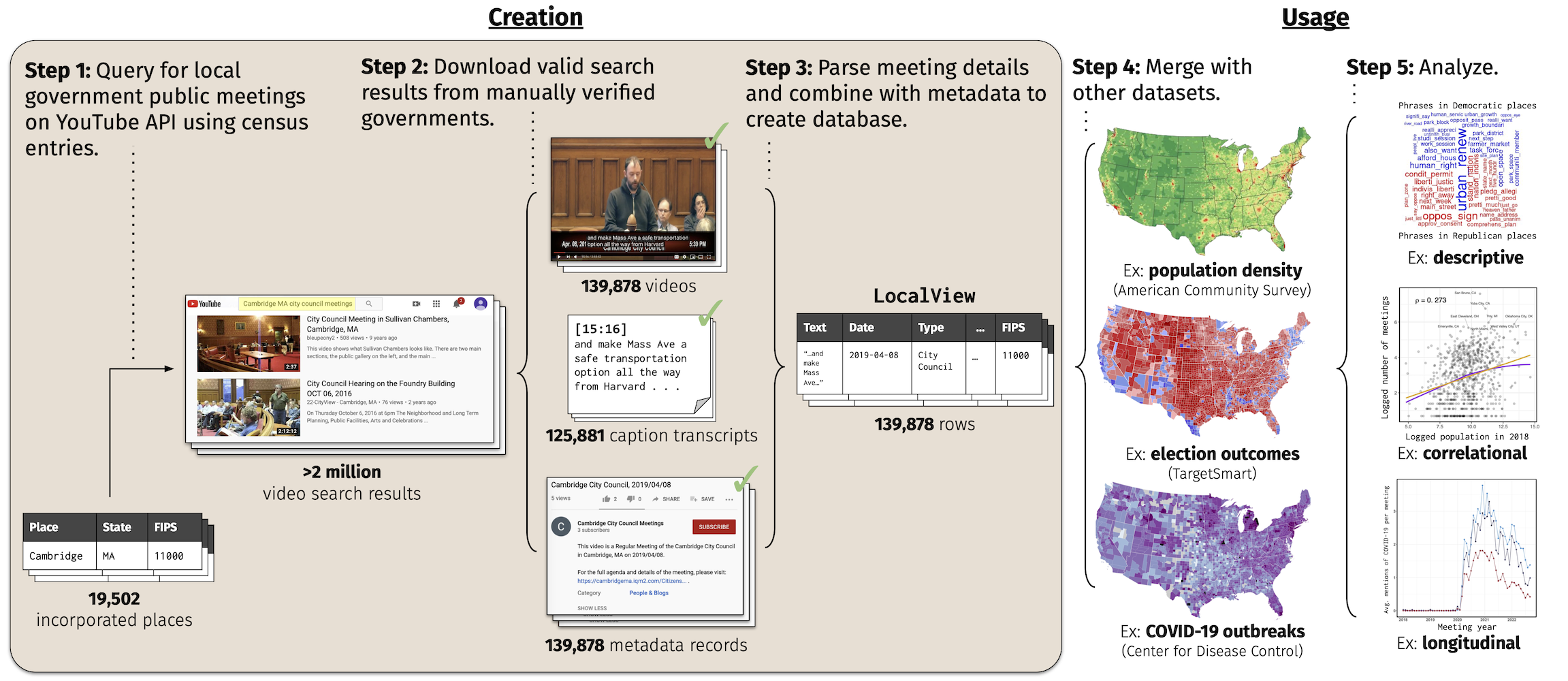
LocalView is an open-source data portal built by Soubhik Barari and Tyler Simko to advance the study of local government in the United States.
It is the largest database of local government public meetings — the central policy-making process in American local government — as they are captured and uploaded to YouTube.
LocalView is continuously collected, processed, and publicly for analysis through an automated pipeline described below.
Here are two ways to started with analyzing LocalView data:
Step 1. Make an account on Harvard Dataverse. Log in and retrieve (or re-generate) your API Token.
Step 2. Install the dataverse package (to pull from the Dataverse repository) and arrow package (to interface with the .parquet files) on R.
install.packages("dataverse")
install.packages("arrow")
Step 3. Load the package in R and set the home server and your API token.
library(dataverse)
Sys.setenv("DATAVERSE_SERVER" = "https://dataverse.harvard.edu",
"DATAVERSE_KEY" = "<my token>")
Step 4. Retrieve the particular slices of data you would like to work with (see package tutorials). Note that this may take a while depending on the files you need:
meetings_2016 <- get_dataframe_by_name(filename = "meetings.2016.parquet",
dataset = "10.7910/DVN/NJTBEM",
.f = arrow::read_parquet)
Step 1. Make an account on Harvard Dataverse. Log in and retrieve (or re-generate) your API Token.
Step 2. Install the pyDataverse package, the pandas package on Python, and the pyarrow package on Python on your shell terminal of choice.
pip3 install pyDataverse
pip3 install pandas
Step 3. Load the Dataverse package in Python and set the home server and your API token.
from pyDataverse.api import NativeApi
from pyDataverse.api import DataAccessApi
api = NativeApi("https://dataverse.harvard.edu", "<my token>")
Step 4. Download the particular slices of data you would like to work with (see package tutorials):
data_api = DataAccessApi('https://dataverse.harvard.edu/')
localview = api.get_dataset("doi:10.7910/DVN/NJTBEM")
localview_files = localview.json()['data']['latestVersion']['files']
meetings_2016 = data_api.get_datafile("<file id for meetings.2016.parquet>")
with open("meetings.2016.parquet.zip", "wb") as f:
f.write(response.content)
Step 5. Unzip the resulting files using the methof of choice and then read in the .parquet file using the pandas package:
import pandas as pd
meetings_2016 = pd.read_parquet('meetings.2016.parquet', engine='pyarrow')